69.5%
Valid positions generated
4.3×
The random baseline rate
Features
- — Applied D3PM discrete diffusion to chess position generation — a setting not studied in prior work, treating FEN board states as token sequences to corrupt and denoise.
- — Custom FEN tokenizer converting each board state into a 72-token integer sequence — 64 square tokens plus 8 metadata tokens encoding castling rights, en passant, and move counters.
- — DDiT-Llama transformer denoising network with 30.8M parameters, 512-dimensional embeddings, and 6 layers trained with AdamW and linear warmup on an NVIDIA B200 GPU.
- — Two-level evaluation framework — Level 1 checks syntactic validity via python-chess, Level 2 compares distributional realism against training data and a random baseline using KL divergence across four structural metrics.
- — Trained on tactically rich puzzle positions from the Lichess open database, giving the dataset a distinctive statistical fingerprint the model must implicitly reproduce.
- — Achieves 69.5% valid position generation — more than four times the 16.3% random baseline rate — with no chess rules ever provided to the model.
Results
The model excels at learning pawn structure — closely matching the training distribution on white pawn count and passed pawn metrics. Material balance and total material are learned less precisely, with the model showing a systematic bias toward piece-rich opening positions.
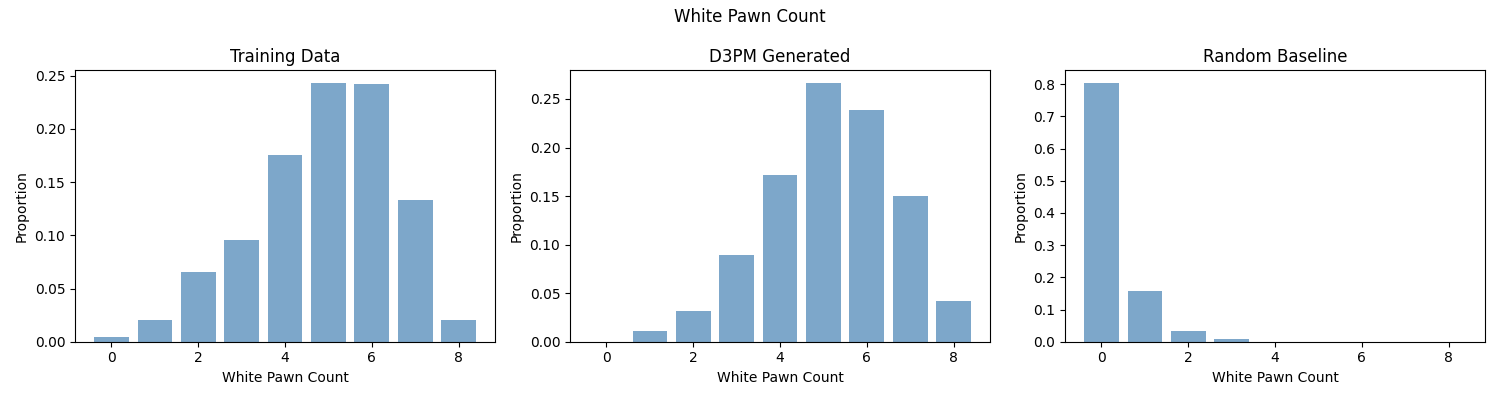
White Pawn Count Distribution
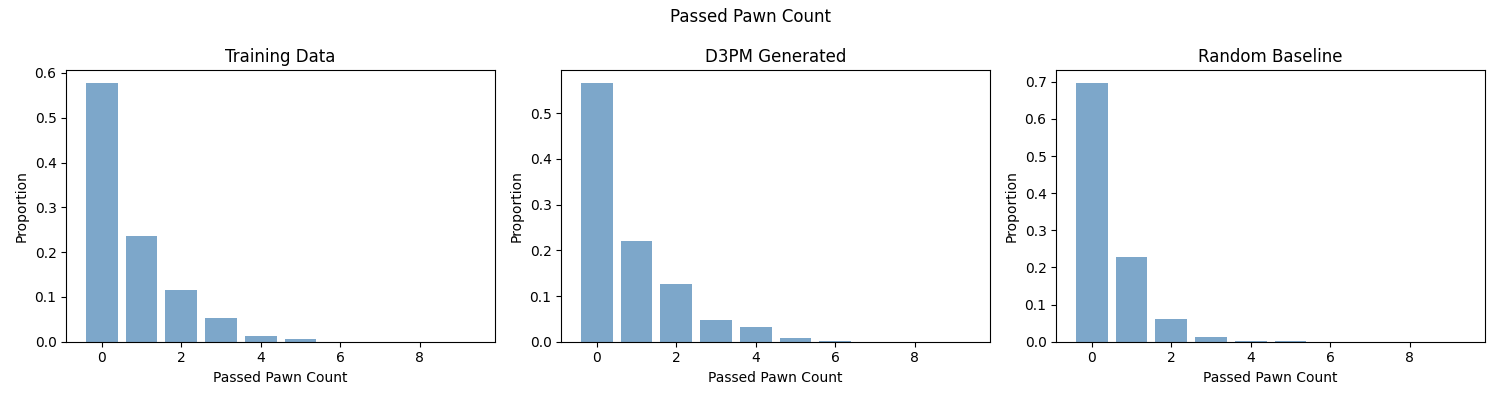
Passed Pawn Count Distribution
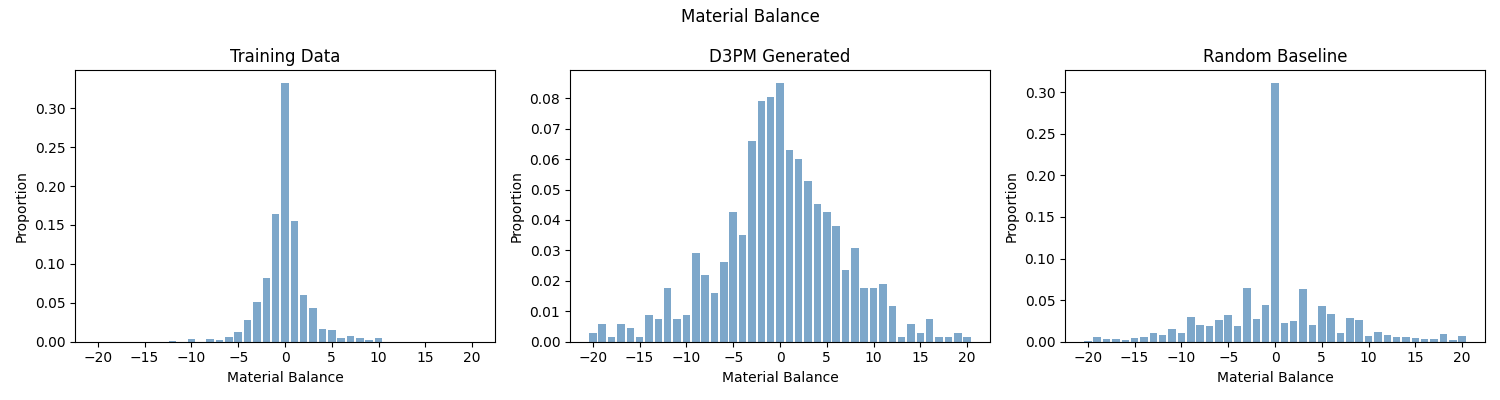
Material Balance Distribution
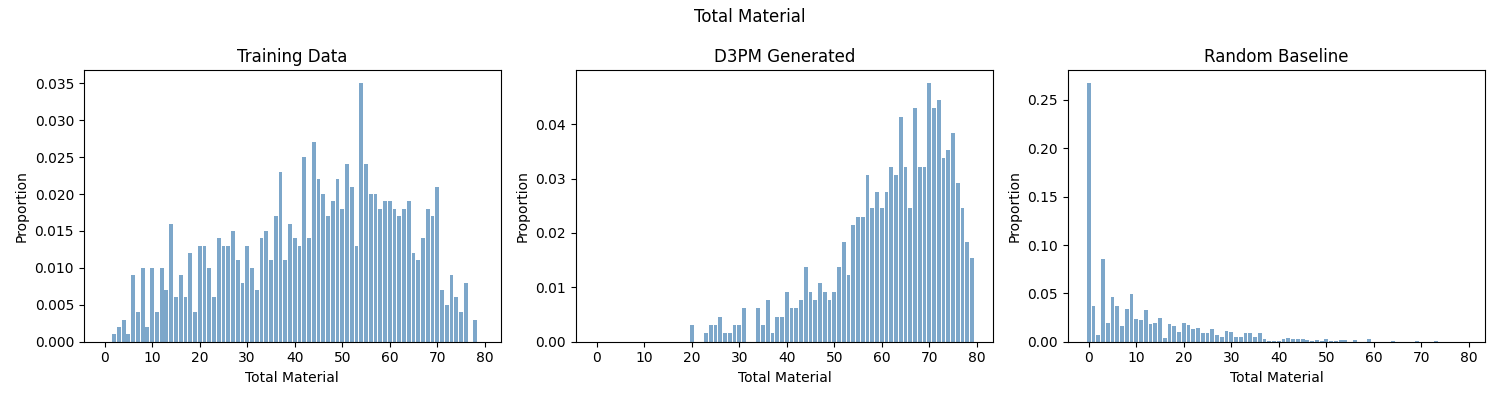
Total Material Distribution